

Application of decision trees in sales campaign
The sales period is a time of increased turnover in both the online channel and bricks & mortar stores. One of the biggest challenges in this time is a proper adjustment of the marketing campaign to new and existing Customers. To define the target audience of a sales campaign, you can use the mechanisms of data exploration with respect to Customers who have already made a purchase in your online or bricks & mortar store.
Data exploration is a process of discovering generalised rules and knowledge contained in databases, based on statistical methods and artificial intelligence techniques. The idea of data exploration consists in using the computer’s speed to find regularities in accumulated data that are hidden from man (due to time constraints). There are many data exploration techniques derived from well-established fields of science such as statistics and machine learning. One of the most important issues pertaining to the field of machine learning is the selection of a classification method.
How can I use data exploration in e-commerce marketing?
To determine the target Customers who are very likely to make a purchase during the sales campaign, you can use the classification method referred to as a decision tree. Decision trees are a graphic method of supporting the decision-making process. The algorithm of decision trees is also applied in machine learning for acquiring knowledge based on examples. The concept of Bugging consists in building experts for a subset of tasks. In this case, a subset of problems is randomly selected with replacement among all problems to be solved and then an expert is sought for this subset. In this algorithm, a subset is randomly selected from among all elements of the data set, and a prediction model is built for this subset. Next, another subset of vectors is again randomly selected with replacement and another model is built for it. The whole procedure is repeated a few times, and all models that have been built are used for voting at the end.
Decision tree methods include a few algorithms. Our case uses the algorithm named Random Forest, consisting in creating many decision trees based on a random data set. The idea behind this algorithm is to build a group of experts from randomly selected decision trees, where – unlike traditional decision trees – random trees are built following a principle according to which the subset of features analysed in a node is selected at random.
The characteristics of Random Forest Algorithm
Compared to other algorithms, it’s best in terms of accuracy; it works effectively with large databases; it retains its accuracy if there’s no data or it gives an estimate of which variables are important to the classification; there’s no need to prune the trees; forests can be saved and used in the future for another data set; it doesn’t require knowledge of an expert. Single classifiers of the random forest are decision trees. Random Forest Algorithm is very suitable for analysing a sample where the observation vector is large.
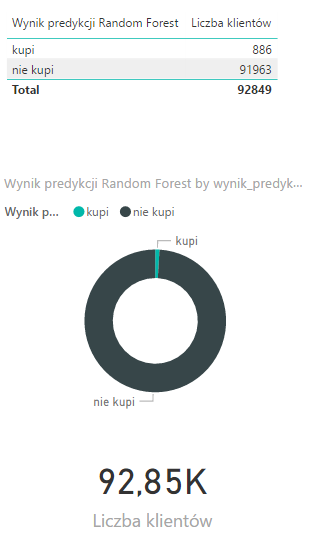
An analysis of customers’ transactions in the online channel was conducted using Random Forest. The algorithm was launched based on the following parameters:
- Purchase made in a city
- Size of the city population
- Number of days since first purchase
- Number of Customer’s orders
- Number of products in order
- Average discount in order
Algorithm results: 886 customers were classified who are very likely to make a purchase during the next sales action.
